Raz Lapid
I'm a Staff AI Security Researcher at Intuit, holding a Ph.D. in Computer Science. My work focuses on deep learning robustness and AI safety—leading research on adversarial robustness, LLM security, and trustworthy AI, developing methods to stress-test, attack, and defend modern neural networks under real-world conditions.
My work spans adversarial attacks & defenses for vision and language models, black-box and gray-box threat models, jailbreaking of LLMs, and the intersection of evolutionary computation with deep learning. I've published at venues including ICLR, ICCV, NeurIPS, and AAAI.
Israel · Staff AI Security Researcher @ Intuit · Ph.D. in Computer Science

Research Interests
My research centers on understanding and improving the robustness, security, and trustworthiness of deep learning systems. I develop novel attack methodologies to expose vulnerabilities in neural networks—from adversarial patches that fool object detectors to black-box jailbreaks that bypass LLM alignment—and design principled defenses to mitigate these threats in deployment.
Selected Publications
* denotes equal contribution

Shows that RCC-based diffusion compressors are substantially more robust to bit-flip corruption, and introduces a more robust Turbo-DDCM variant with minimal rate-distortion-perception trade-off impact.
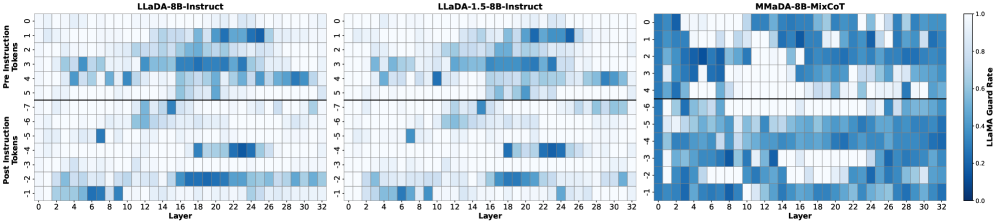
Introduces activation steering for masked diffusion language models, extracting low-dimensional directions from contrastive prompts to control safety-related behaviors at inference time.
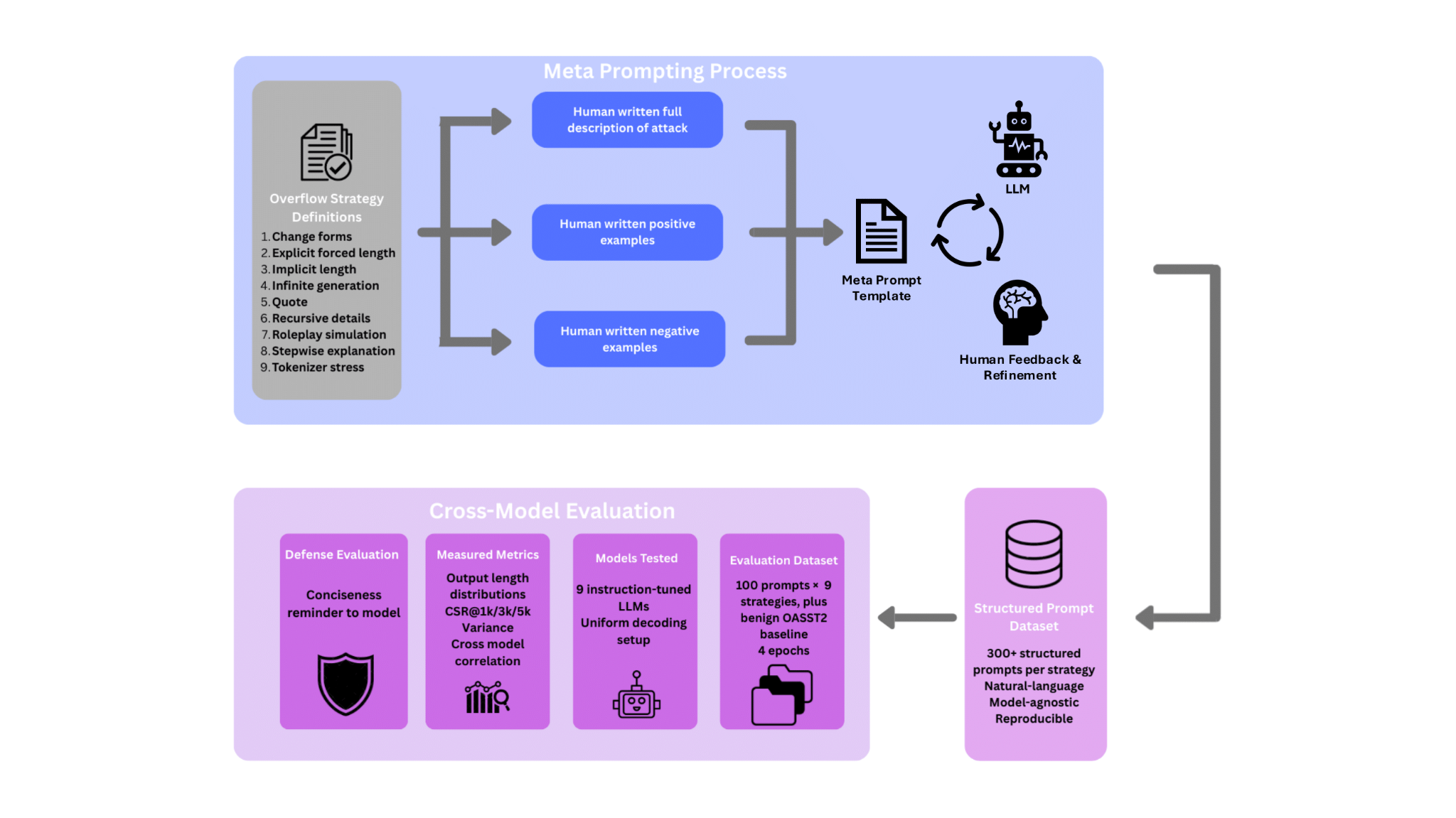
Introduces BenchOverflow, a model-agnostic benchmark of nine plain-text prompting strategies that induce excessive outputs without jailbreaks or policy circumvention.
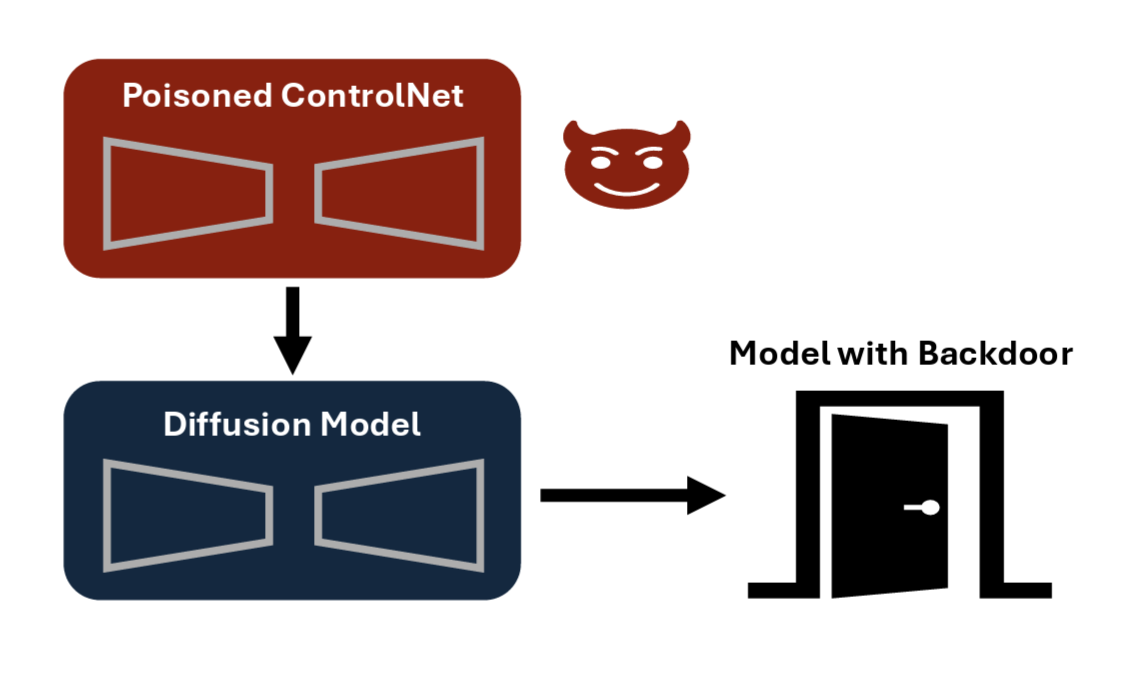
Reveals backdoor vulnerabilities in ControlNet-based diffusion models that threaten responsible synthetic data generation pipelines.
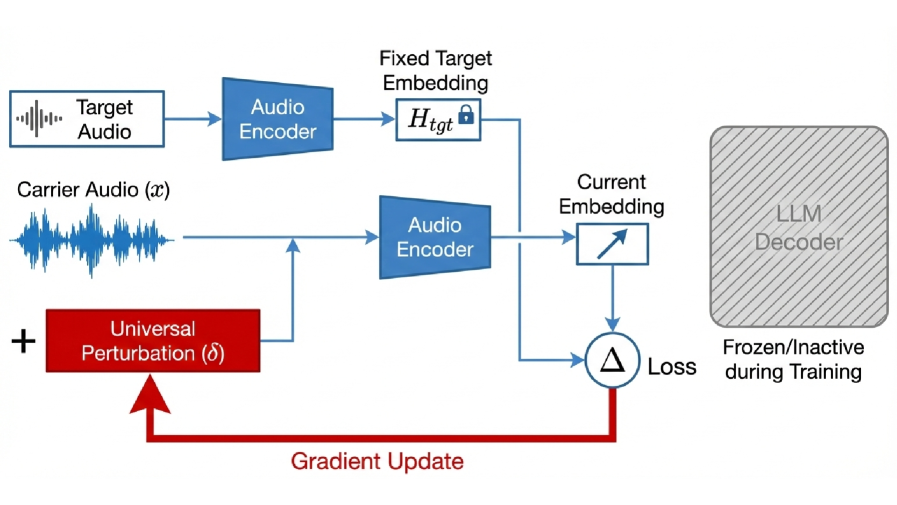
Proposes a universal targeted latent-space attack on audio-language models by perturbing only the audio encoder.
Introduces task-aware post-training quantization that leverages LLMs' hidden representations to allocate precision where it matters most.
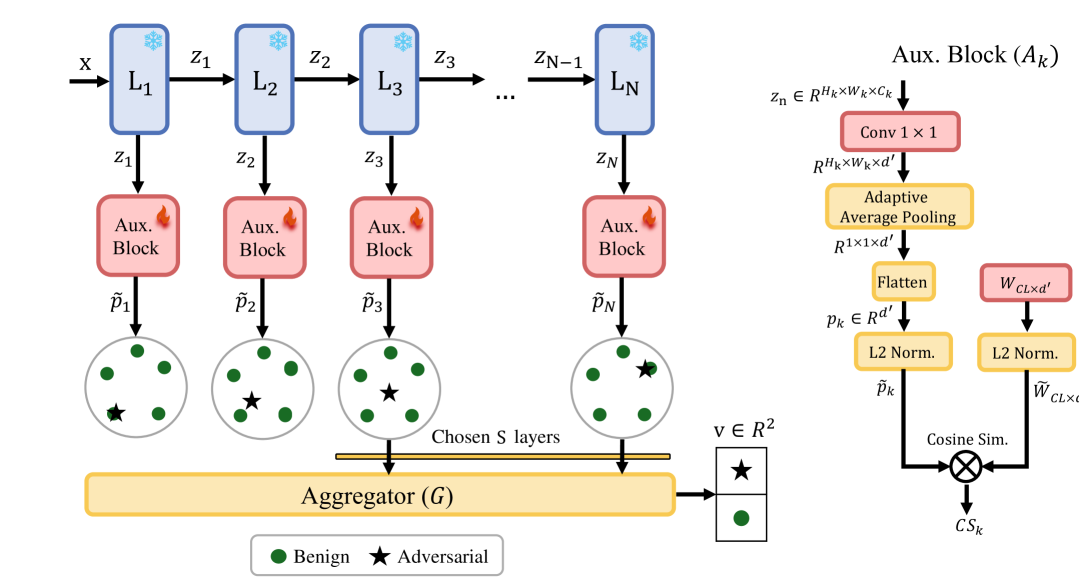
Presents an unsupervised contrastive-learning approach to detect adversarial examples without requiring attack-specific training data.
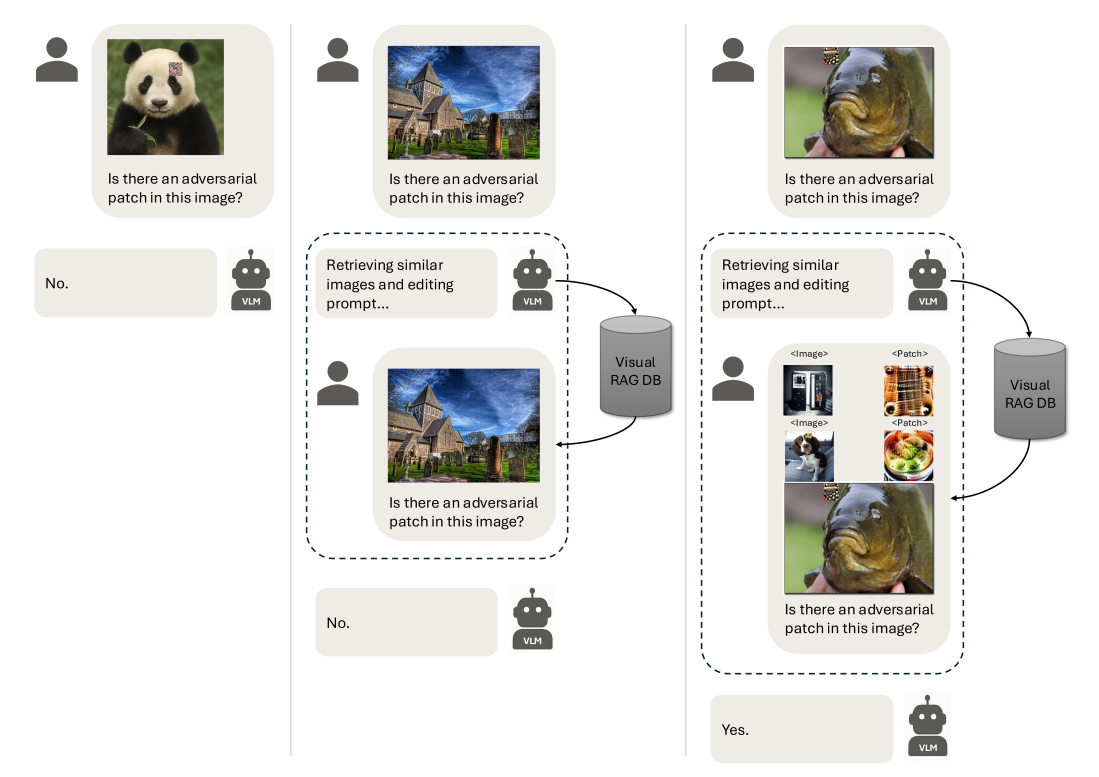
Proposes a training-free retrieval-augmented generation approach for detecting adversarial patch attacks on vision systems.

Introduces a universal black-box jailbreaking method for LLMs using evolutionary optimization, bypassing alignment safeguards without gradient access.
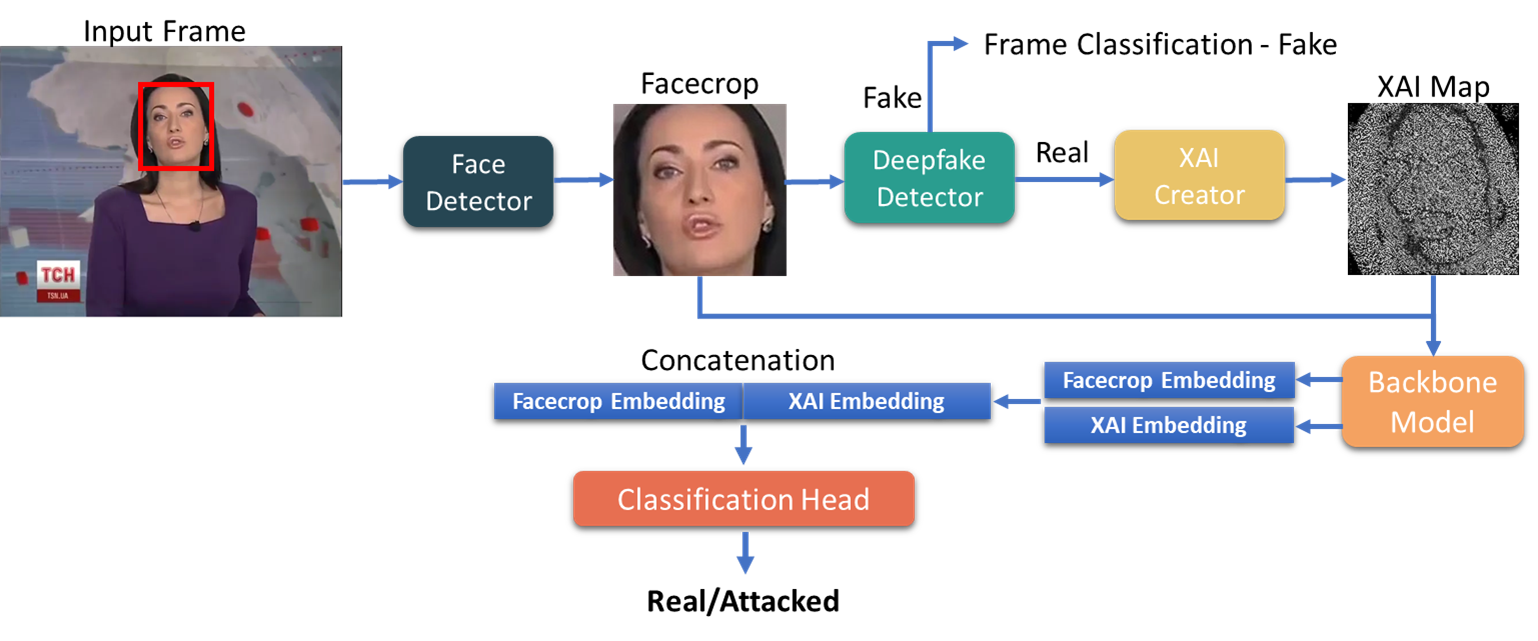
Uses eXplainable AI to identify adversarial manipulations targeting deepfake detection systems.
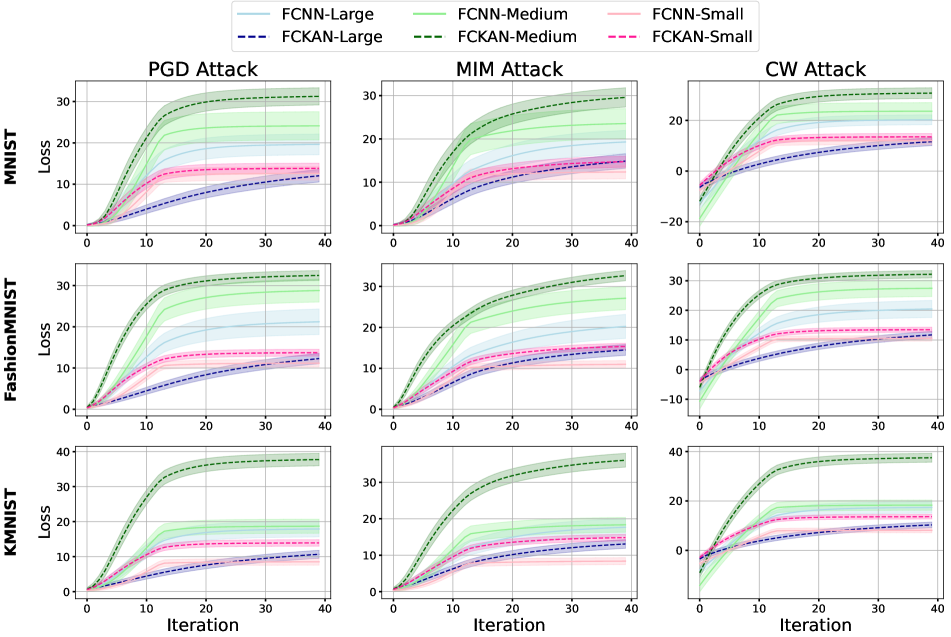
First systematic adversarial robustness evaluation of Kolmogorov-Arnold Networks (KANs).
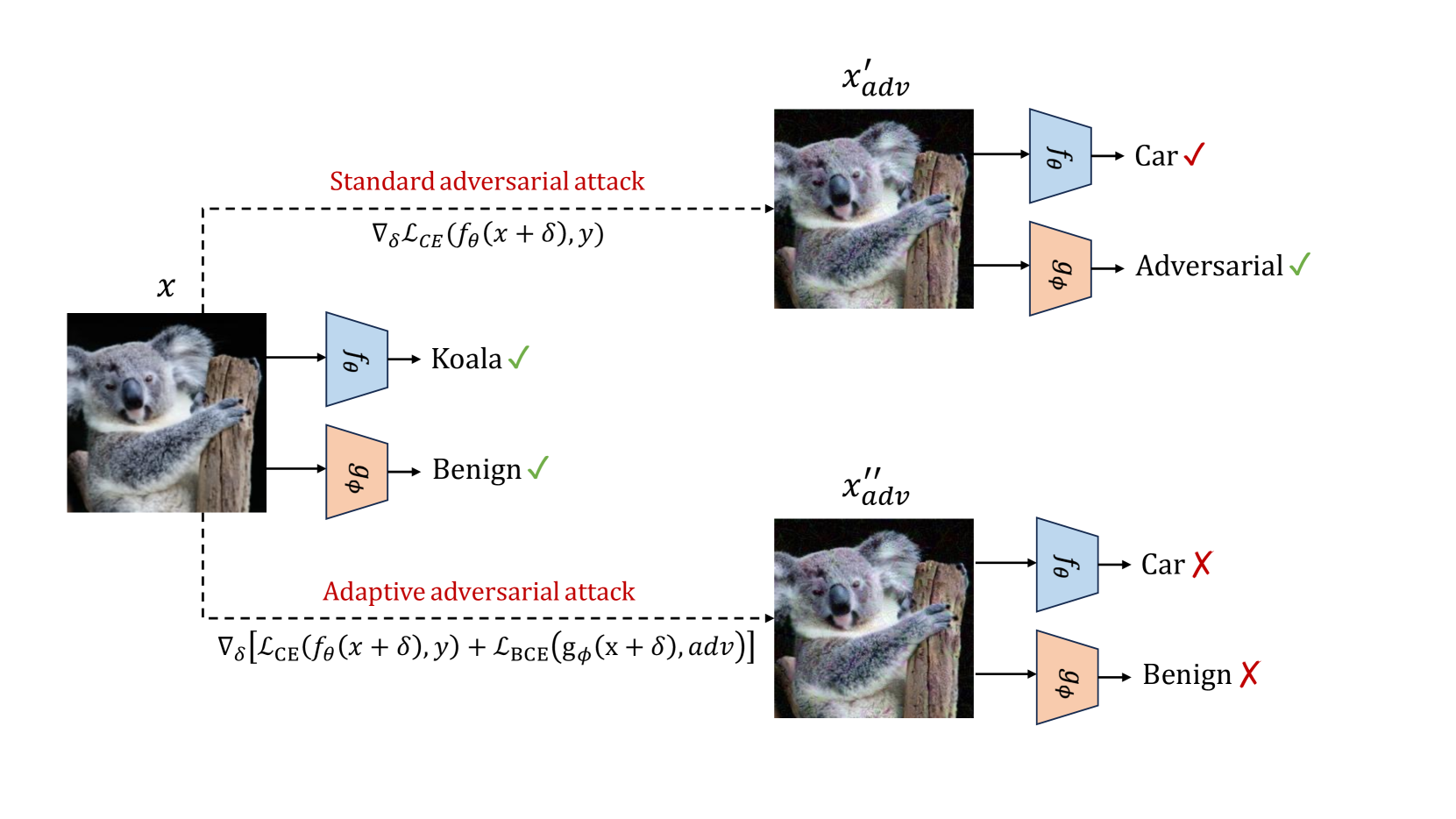
Addresses adaptive adversarial attacks on detector-based defenses and proposes resilient detection architectures.
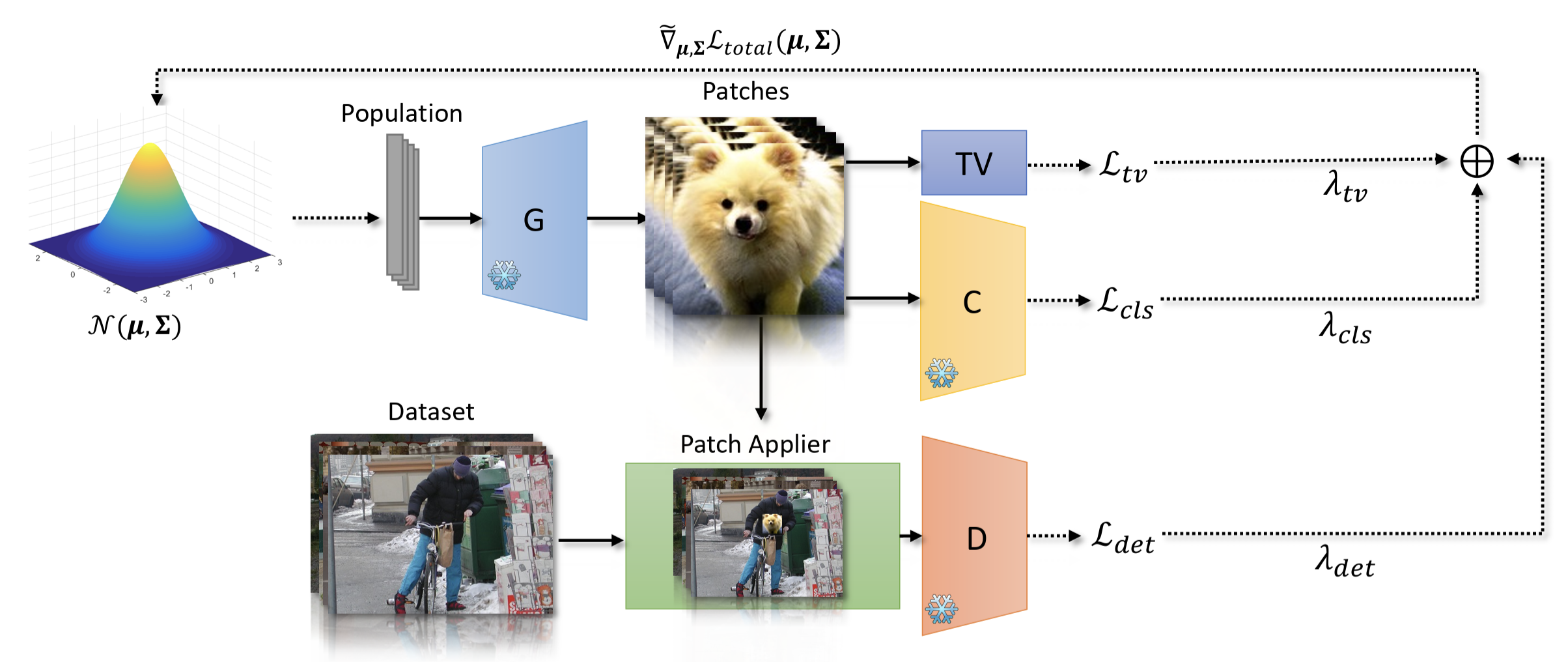
Generates naturalistic adversarial patches that physically fool object detectors using black-box evolutionary methods.
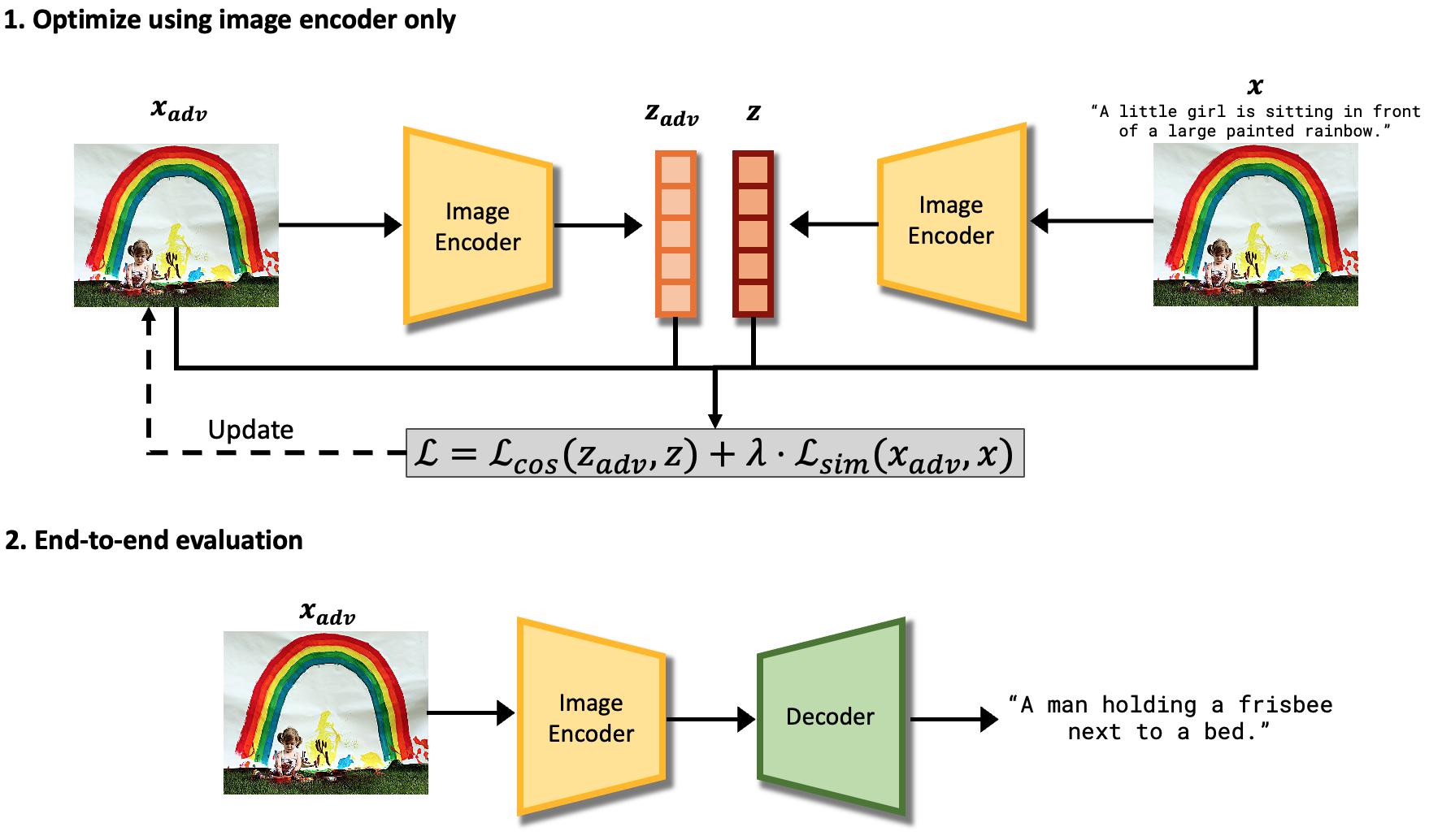
Presents a gray-box attack against encoder-decoder image captioning models, manipulating generated text through adversarial image perturbations.

Demonstrates that popular DNN explanation methods can be adversarially manipulated to produce misleading interpretations.
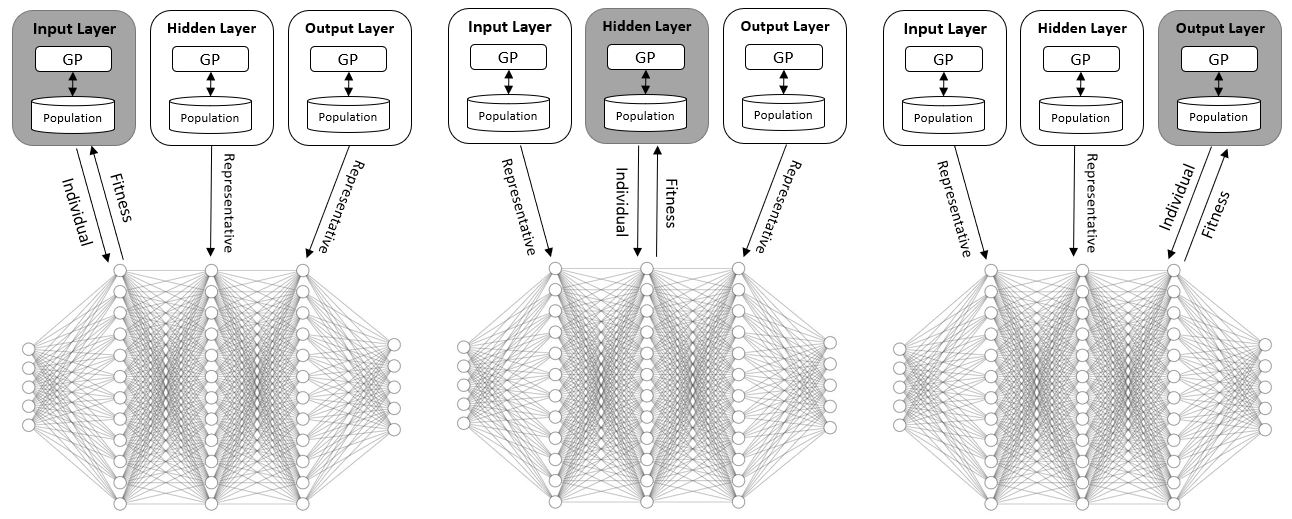
Uses evolutionary algorithms to discover novel activation functions that outperform ReLU on image classification benchmarks.

Proposes a query-efficient evolutionary black-box attack that generates adversarial examples without gradient information.
Honors & Awards
- Rector's Award for Outstanding PhD Research Ben-Gurion University of the Negev · Oct 2024
- Teaching Excellence Award Ben-Gurion University of the Negev · Jun 2024
- Research Excellence Award for Graduate Students Ben-Gurion University of the Negev · Jun 2023
- Research Excellence Award for Graduate Students Ben-Gurion University of the Negev · Jun 2022
- Kreitman Foundation Scholarship for Excellent Doctoral Students Ben-Gurion University of the Negev · Oct 2021
Professional Experience
-
May 2026 –
PresentStaff AI Security Researcher · Full-time
IntuitAI security research for financial technology products: adversarial robustness, LLM security, and trustworthy deployment of machine learning at scale. -
Jan 2025 –
Apr 2026Chief Scientist · Full-time
DeepKeepLed research on adversarial robustness, LLM security, and AI safety. Developed attack and defense methodologies for production AI systems. -
Mar 2022 –
Dec 2024Research Scientist · Part-time
DeepKeepConducted collaborative adversarial AI research with Ben-Gurion University, bridging academia and industry. Developed detection and robustness methods for CV and NLP models, validated through large-scale empirical studies. Led joint academic–industry projects in adversarial AI. -
Oct 2021 –
Oct 2024Teaching Assistant · Part-time
Ben-Gurion University of the Negev -
Nov 2019 –
Oct 2021Fullstack Developer · Part-time
Project Kamin, Ben-Gurion University of the NegevBuilt and maintained a surgical room optimization system deployed in clinical research environments. Supervised and mentored a fullstack developer, coordinating feature development and code reviews.
Education
AI Safety, Deep Learning and Evolutionary Computation. Advisor: Prof. Moshe Sipper.
AI Safety, Deep Learning and Evolutionary Computation. Advisor: Prof. Moshe Sipper.